
How to Write a Compiler
Since there isn't that much beginner info out there about this topic, heres a very rough run down of what I know about the basics of writing your own compiler, in particular about how the CPU works and how to generate code for it.
CPU/bytecode interpreter
A bytecode interpreter works just like a CPU, the difference being that it is in software, while the CPU is actual hardware. So all a fake or real CPU does is take a list of instructions and fetch them one by one.
To properly do that, there is one variable (in a real CPU, this is a register) that contains the position of the current instruction. This is called the program counter or PC for short, and is basically just the memory address of whatever command it is to execute.
Once an instruction finishes, the CPU adds to the PC to make the pointer point at the next instruction (or in the case of a conditional or loop, it rewinds the PC back to the start of the loop, or jumps over the else section, or whatever.
So its fairly easy to create a bytecode interpreter. Its just a loop:
#define NO_OP 0
#define PRINT 1
#define END 2
struct Instruction { int instructionType; int param1; int param2; };
Instruction *currentInstruction = LoadCodeFromDisk();
while( currentInstruction )
{
if( instructionType == NO_OP )
currentInstruction++;
else if( instructionType == PRINT )
{
DoPrint( currentInstruction->param1, currentInstruction->param2 );
currentInstruction++;
}
else if( instructionType == END )
currentInstruction = NULL;
else
exit(1); // UNKNOWN INSTRUCTION! BLOW UP!
}
So all that generating machine code or byte code is, is really adding items to an array of structs. Of course, if you want to generate Intel machine code its a little more complicated, because instructions can be different size, so you can't use a classic array, but you can write the raw data to a file or memory block just the same.
Generating code that jumps
If you've ever programmed BASIC, you've probably seen the following program:

1 PRINT "Hello World" 2 GOTO 1
This is an endless loop. Line 1 prints some text to the screen, and line 2 jumps back to line 1. Once line 1 is done, we continue to line 2 again, which jumps back to line 1, forever and ever until someone turns off the computer. So all GOTO does is change the currentInstruction from our above example, the program counter.
currentInstruction = 1;
You can implement GOTO the same way in your bytecode interpreter. However, since you usually don't know what address your code will be loaded at (and it definitely won't be address 1), you will generally write your code so it jumps relative to the current instruction's location. So our version of GOTO, the JUMPBY instruction, would be
currentInstruction += currentInstruction->param1;
For our pseudo-machine-code:
PRINT "Hello World" JUMPBY -1
With this instruction under your belt, you can quickly implement conditional statements like if. An if-instruction is simply an instruction that looks at a location in memory (whose address could be provided as param2) and if that location is 1 (true), jumps by param1. Otherwise it does the usual currentInstruction++.
The conditional GOTO is the basic building block of all flow control. If/else:

1 FOO=1 2 GOTO 5 IF FOO 3 PRINT "Foo is false." 4 GOTO 6 5 PRINT "Foo is true." 6 END
loops:
1 FOO=0 2 GOTO 6 IF FOO 3 PRINT "Repeating." 4 DO_SOMETHING_THAT_COULD_CHANGE_FOO 5 GOTO 2 6 PRINT "End of loop" 7 END
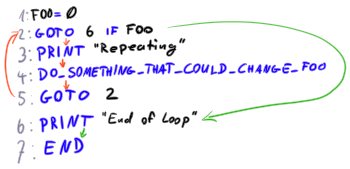
Note that bytecode has no operators, no expressions, no precedence. You provide operations in the order it is supposed to execute them. If you want to compare two strings, you do so in the instruction at the top of the loop, save its result to FOO, then loop over FOO:
1 FOO=COMPARE("a","b")
2 GOTO 6 IF FOO
3 PRINT "Repeating."
4 DO_SOMETHING_THAT_COULD_CHANGE_FOO
5 GOTO 1
6 PRINT "End of loop"
7 END
(Note how line 5 jumps to line *1* here, i.e. every time through the loop, the condition is evaluated, then the conditional GOTO tests it)
Retroactive code generation
Now how do you generate code for this? How do I know, before I have read and generated the individual instructions, what line the GOTO in line 2 will have to jump to?
Well, you don't. Instead, what you do is write out the GOTO as
2 GOTO 0 IF FOO
and then later, when you reach the end of the loop in line 5, where you write out the GOTO that jumps back to the condition, you simply change the destination of line 2 after the fact. This is usually fairly easy if you write a function for parsing every syntax element. Take the following C-like program:
strcpy( txt, "a" );
while( compare(txt,"b") )
{
print("repeating");
do_something_that_could_change_txt();
}
print( "End of loop" );
You'd have a function CompileOneLine() that reads one line and looks at the first word. If it is if, it calls CompileIfLine(), if it is while it calls CompileWhileLine(), if print, CompilePrintLine(), etc.
CompileWhileLine() would look something like:
void CompileWhileLine()
{
int conditionOffset = ReadAndCompileExpression( "FOO" );
int conditionalGotoOffset = WriteInstruction( "GOTO IF", 0, "FOO" );
if( NextChar() == '{' )
{
SkipChar('{');
while( NextChar() != '}' )
CompileOneLine();
}
else
CompileOneLine();
int gotoOffset = WriteInstruction( "GOTO", conditionOffset );
SetDestinationOfGoto( conditionalGotoOffset, gotoOffset );
}
And since we call CompileOneLine() again to read the lines inside this while statement, we can nest while statements.
Variables
As demonstrated, this byte-code has one big downside: How do we do variables? We can't put the variables in with the code, because that would mean that when a function calls itself, it would use the same variables as its previous iteration. So we need some sort of stack to keep track of the most recent function's variables. And that is what the stack in programming languages like C is.
To manage the stack, the code for a function has a prolog and an epilog. That is, a few instructions at the start, before any actual commands that the function contains, where it makes the stack larger to reserve space for the variables we need, and a few more after the end to get rid of them again. In our BASIC-like pseudocode, this could look like:
PUSH 0 // Reserve space for 3 int variables: PUSH 0 PUSH 0 // ... actual code goes here POP // Get rid of no longer needed 3 int variables POP POP
Now since we sometimes need a variable just for a short while (e.g. FOO for holding the loop conditions result to hand off to the conditional GOTO instruction), it would be kind of awkward to find our variables by counting from the back of the stack. We'd have to remember how many temporary values are on the stack and account for them on each access. So to simplify that, we have a base pointer. A base pointer is another variable/register, like our program counter before. Before we push our variables on the stack, we write the size of the stack into the base pointer.
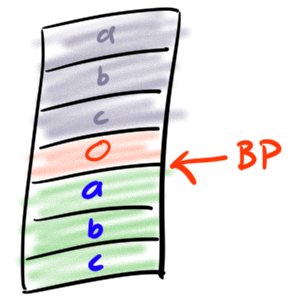
PUSH basePointer // Save the old basePointer (for whoever called us) SET_BASEPOINTER // Write current stack size to basePointer PUSH 0 PUSH 0 PUSH 0 // ... actual code goes here POP POP POP POP_BASEPOINTER // Restore the saved base pointer into the basePointer
Now, to use a variable, we can simply access it relative to the basePointer, i.e. basePointer[0]=1. No matter how many variables we add, these numbers stay the same for the lifetime of our function.
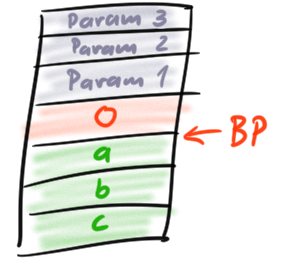
And once we have this, we can also implement parameters. Parameters are simply variables at a negative offset. Since whoever calls us pushes parameters on the stack right before calling us, they all can be found right before our saved basePointer. So basePointer[-2] is parameter 1, basePointer[-3] parameter 2 etc. This means the parameters need to be pushed in reverse order, but that's all there is to it.
Returning
Given the above, it comes as no surprise that you can't just return from your function. You need to make sure that, before you return, your clean-up code runs. So what we usually do is, we make a note of the position at which the clean-up code starts, put a RETURN statement right at its end, and then whenever the code wants to return, we just write the return value somewhere on the stack, GOTO the clean-up code and let it return.
Of course, you'll have to remember all spots that GOTO that code, because when you write them, the clean-up code won't have been written yet, and fill it out in retrospect. But if you got this far, that's all old hat to you.
Strings and other (bigger) data
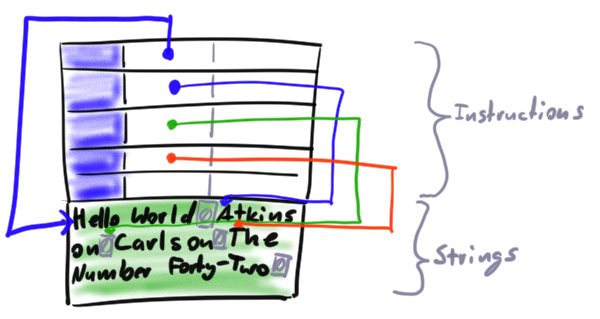
As you may have noticed, our instructions only have two ints as parameters. What if you need to e.g. provide a format string to printf? Well, you'll need an instruction that loads a string constant. Pushes its address on the stack, which the print command can then grab and display.
Commonly, what one does is simply write the strings in the same file (or memory block) as the bytecode, e.g. right after the actual instructions, and then load the whole thing into RAM. Since you know how big your block of code is after you've written it, you can retroactively fill out the offset from the instruction to the string it is supposed to push on the stack, and at runtime, the instruction can use currentInstruction +n to get a pointer to it and push that on the stack.
And that's pretty much how you create a bytecode interpreter and generate bytecode (and in a simplified form, this is how you generate machine code).
For further reading, I recommend: Intel Assembler on macOS X and Generating machine code at runtime.